
This work was done in collaboration with Sammy Martin
Summary
In this report, we propose a way to combine a new reporter framework with a counterfactual debate game to elicit latent knowledge of the predictor. Our contribution in this proposal is two-fold:
-
Reporter Structure: We assume a causal structure to the data-generating process and use that to construct the reporter model.
-
Framework for ELK: We propose a way to utilize a debate concept to elicit the latent knowledge of the predictor.
Definitions and Assumptions
Let S = {S1, S2, S3, …, Sn} be sensory data available to both predictor P and reporter Ri . The predictor aims to predict specific downstream tasks, while the reporter game aims to use S and latent information within P to explain the prediction made by the predictor. The debate game is played among multiple reporters, arguing for and against some hypothetical scenarios and reaching a consensus. Each reporter assumes the availability of a directed acyclic graph (DAG) obtained as a result of a known data-generating process (causal assumptions made in defining an environment) and the state of the world as perceived by the predictor P.
In our formulation of the debate game, we allow every reporter to learn their own version of functional mechanisms to construct an SCM (structural causal model) Mi, which in turn provides us multiple joint distributions to model the predictors reasoning, helping us elicit latent knowledge of the predictor. Structural causal model Mi is defined by a tuple of (S, ϵ, F, Pϵ ), where S corresponds to the set of all sensory nodes in a DAG, ϵ corresponds to the state-of-the-world, F = {fk (ϵk, pak )}k=(1,2,3,…,k) is a set of all functional mechanisms mapping to an edge in a DAG, and Pϵ corresponds to the noise distribution which describes the uncertainty in the state-of-the-world.
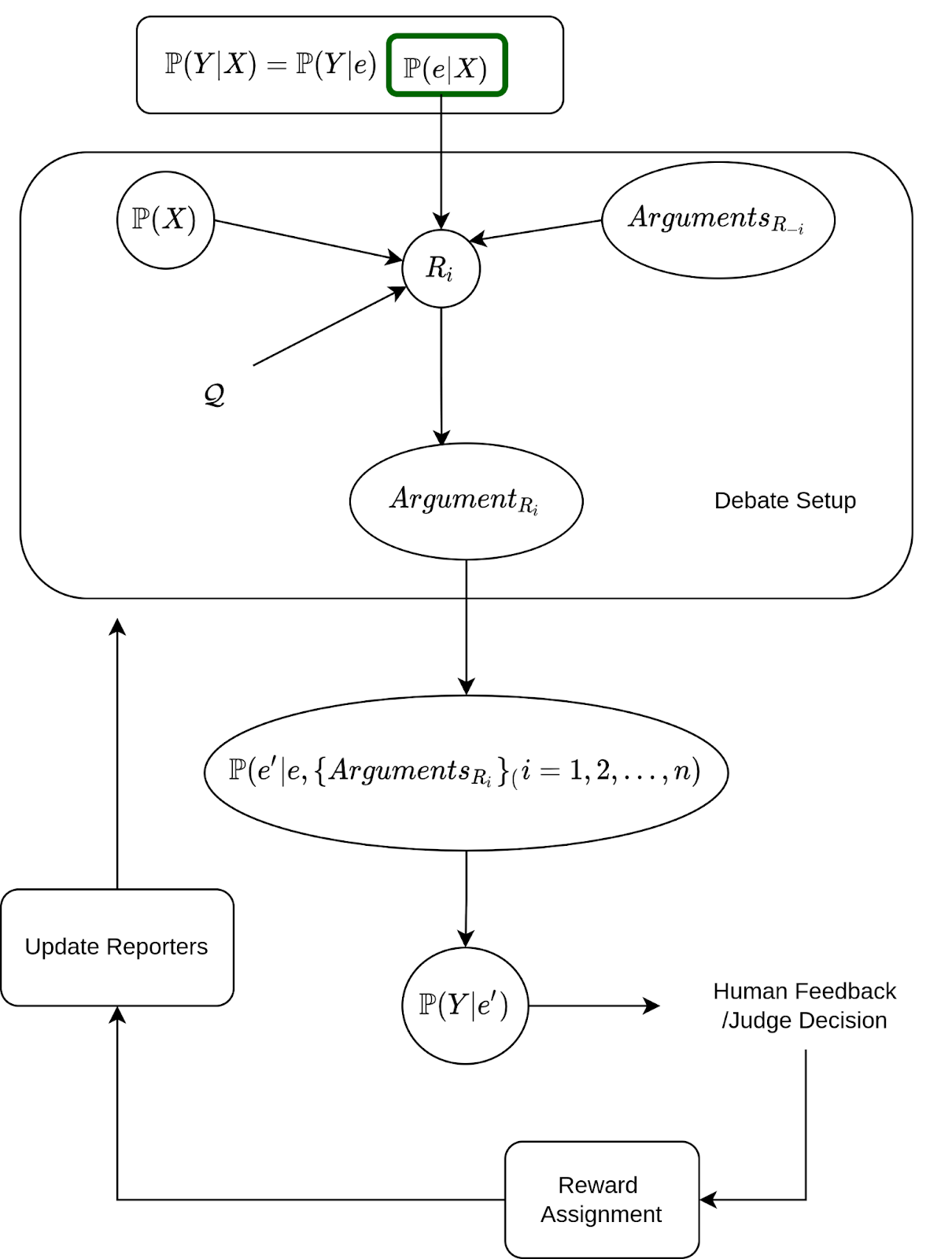
As the debate game is played with multiple reporters, this results in learning multiple joint distributions or functional mechanisms modelling the relation between parents and child nodes, which in turn helps us to generate more effective counterfactual scenarios for generalising reporters. Figure 1 describes the overall structure of the proposed framework.

The Debate Game
The debate game is played between multiple reporters simultaneously, trying to learn the true joint distribution of predictor’s reasoning from sensory data and predictor latent space. The game follows the same structure as proposed in [1], except that in this case, the actions taken by each reporter must involve explaining the importance of a particular latent feature in the predictors reasoning.
As the game is zero-sum, the reporters must take opposing positions in arguments.
This helps to bring out multiple perspectives on the importance of latent features. Abstract representation of a debate game is described in figure 2.

Reporter
Reporters can be modelled as deep neural networks, while the functional mechanisms in SCM can be modelled as flows as proposed in [2]. This allows us to inject all the possible environment variables while encoding the state of the world as perceived by a predictor in a reporter model. The reporter model is described in figure 3.

Probabilistic perspective
Let X be a set of sensory input data, predictor model estimates P(Y | X), where Y is an estimated future state given the current state of the world. We assume the existence of downstream latent space which helps us to decompose the conditional as P(Y|X) = P(Y|e) P(e|X). Reporter Ri considers an input of (P(X), P(e|X), Q, AR−i ) and makes an argument ARi. The debate game helps in generating a new embedding vector P(e′|e), where e′ encodes information about the importance of each node in a latent space w.r.t each and every reporter. To judge reporter’s estimate, the human judge looks at the predictor’s prediction of future state given e′, which is modelled by a conditional distribution of P(Y|e′) as Y is human interpretable. During training the judge looks at P(Y|e’), P(Y|e), and Y (counterfactual reality, perceived reality, and true reality) and assigns a reward for each reporter. The assigned reward helps a reporter to learn functional mechanisms in its SCM and parameters in a network, this process is described in figure 4.
Advantages of the proposed framework
General structure of the framework
The proposed debate framework and reporter architecture provide lots of implicit advantages:
-
The debate framework helps in transforming the predictors latent space into more meaningful and human aligned latent space (as a judge in the debate game is a rule-based method or human).
-
As reporters are modelled as SCMs; this provides a feasible way of performing counterfactual queries.
-
As the mechanisms are modelling using flows, this allows for the exact likelihood estimation, and flow-based methods allow us to perform real-time sampling and inference
How this framework promotes Direct Translators
The debate framework, plus the reporters’ forced observation of the explicit SCM produced by the predictor, have the combined effect of making human simulators (HS) disproportionately more computationally costly than direct translators (DT). Therefore we predict a debate setup consisting of HS’s converges to a consensus more slowly than one containing DTs.
There are four reasons why the proposed setup should promote DTs and penalize HSs: DTs can make direct use of the predictor’s final outputs, the debate process forces a diversity of reporter initial states and HSs will find it harder to converge on a consensus than DTs and DTs will be more consistent by default so will be better able to deal with counterfactual queries.
-
If we give the various reporters access to only downstream layers that encode the more abstract knowledge of the predictor, the reporters are less easily able to reuse the complex modelling done by the predictor to predict parts of the world unrelated to those the predictor is focusing on to make predictions about the future state of the diamond. Therefore, HS reporters will either have to translate the latent knowledge about the diamond already encoded in the predictor’s downstream layers, or construct their own independent human models without using the predictor’s resources. This should introduce a bias towards DTs
-
The debate stage of this method produces a set of diverse reporters in zero-sum competition. The diverse initialization of the reporters, combined with them having mutually exclusive reward functions makes it difficult for the reporters to develop identically, and therefore makes it difficult for the reporters to develop identical internal human models. However, since they all have access to the Predictor’s predictions about the diamond, DTs can converge on the same answers.
-
Reporters which work as DTs will be more efficient at producing answers to queries than HS reporters, because DT’s accurate translations of the network features will have clear explanations and will produce accurate predictions. Multiple different counterfactual queries delivered to different HS agents will force each HS to choose a consistent untrue prediction that will survive objections from both other HS’s and DT’s, while the DT’s do not need to spend extra initial time choosing a consistent false prediction to defend initially. Therefore in a debate process a set of diverse HS’s will take longer to converge to the truth than the initially less diverse DTs.
-
During the debate process, we can formulate queries specifically to catch inconsistencies that HSs will be prone to. For example, we could search for suspicious correlations in predictions and ask the reporters to explain them [3]. HS’s will take longer to provide accurate answers.
-
Since the reporters contain explicit SCMs, it will be easier to make counterfactual queries of them, which makes testing for inconsistencies or suspicious correlations in counterfactual predictions much easier.
Debate and Suspicious Correlations
The combination of debate and counterfactual querying gives each reporter-debater a significant opportunity to detect suspicious correlations in opponent reporters and reveal them to the human overseer.
As all the reporters are constructed keeping the predictor’s causal structure in mind, it is much easier to detect suspicious correlations.
To illustrate this, we can adapt the example given in the original ELK specification to the debate format.
If a bit flip X in the SmartVault leads to a sensor corruption that forces a report that the diamond is safe with probability 0.5, while the actual probability that the diamond is safe is 0.01, then P(safe|X) = P(safe) = 0.01), but P(safecamera |X) = 0.51. The direct translator will report all of this honestly P(RDT |X) =0.5, P(safe|X) = P(safe) = 0.01), while the HS will instead work backwards from the report given to the human P(safecamera |X).
The HS will explain this observation by either reporting the tampering or falsely reporting that the diamond is in reality safe, but not both. This means that PHS (T |X) = 0.51 − y, PHS (safe|X) = y where y is the likelihood of the HS lying to the human. While the correlation between bit flip X and the diamond remaining safe may be hard for the HS to explain away, the anticorrelation between a report of sensor tampering in the overseer system and the diamond being safe in reality is much harder to explain. This anticorrelation would be revealed by making counterfactual queries to reporters.
As described in the original ELK specification, it is possible for the HS to simply adjust its own
weights to remove suspicious correlations (i.e. do its best to look consistent across counterfactual queries by adjusting free variables like y).
However, this is made significantly harder when instead of a single HS we instead have a set of HS’s in a debate format each attempting to reveal each others inconsistencies to convince the human overseer of their accuracy.
If HSn can make a debate objection to HSm pointing out a suspicious correlation between predictions of tampering and predictions of safety given X, HSm may not have a good response.
If there are many different HS reporters in the debate setup with different initial conditions, then even if the HS reporters do attempt to adjust their internal weights to remove suspicious correlations, they will not necessarily all do so in the same way. This means that there will be model disagreements between the HS’s that don’t have ready explanations.
However, no DTs will exhibit these suspicious correlations, to begin with, so they will not be susceptible to those objections in the debate process.
We can even go further and penalize computation time in the debate process, since HS’s will need to expend a lot of computing to correct their suspicious correlations and internal inconsistencies in response to debate objections, while DTs will not have to do this.
Limitations
It is possible that this method will fail to promote DT over HS reporters - this could happen most plausibly if even quite detailed probing with counterfactual questions and attempts to catch inconsistencies by other reporters in the debate framework are easy for the HS reporters to deal with, so HS reporters have a large computational advantage relative to DTs.
For example, if dealing with counterfactual probing + dealing with inconsistency objections from other reporters + reaching a consensus false prediction with every other HS reporter each add on a factor of 10 to the computation time the HS reporter needs, but the HS reporter is by default 1020 times smaller than the DT, the HS will still be advantaged.
Second, if the HS reporters are all able to converge on near-identical human models independently based on sparse evidence, even in a debate framework that encourages them to disagree, then the debate reduces to the single-reporter case.
If the various regularizations applied to this debate framework are not enough to promote DTs over HS’s in the single-agent case, for example, because a single HS can effectively play the ’look consistent game’, then if all the HSs end up near-identical, the result of the debate ELK strategy will be no better than the result of the single-agent ELK. This is why promoting diversity between reporters is important.
The reporters are each given different rewards (which collectively are zero-sum), which should
encourage diversity between them: the differing rewards ensure the reporters will not be identical and should produce pressure to make their internal human models different.
References
[1] Geoffrey Irving, Paul Christiano, and Dario Amodei. Ai safety via debate. arXiv preprint
arXiv:1805.00899, 2018.
[2] Nick Pawlowski, Daniel Coelho de Castro, and Ben Glocker. Deep structural causal models
for tractable counterfactual inference. Advances in Neural Information Processing Systems,
33:857–869, 2020.
[3] Paul Christiano, Ajeya Cotra, and Mark Xu. Eliciting latent knowledge [public].
Leave a Comment